

“If you can cache everything in a very efficient way,
you can often change the game”
We software engineers often face problems that require the dissemination of a dataset which doesn’t fit the label “big data”. Examples of this type of problem include:
- Product metadata on an ecommerce site
- Document metadata in a search engine
- Metadata about movies and TV shows on an Internet television network
When faced with these we usually opt for one of two paths:
- Keep the data in a centralized location (e.g. an RDBMS, nosql data store, or memcached cluster) for remote access by consumers
- Serialize it (e.g. as json, XML, etc) and disseminate it to consumers which keep a local copy
Scaling each of these paths presents different challenges. Centralizing the data may allow your dataset to grow indefinitely large, but:
- There are latency and bandwidth limitations when interacting with the data
- A remote data store is never quite as reliable as a local copy of the data
On the other hand, serializing and keeping a local copy of the data entirely in RAM can allow many orders of magnitude lower latency and higher frequency access, but this approach has scaling challenges that get more difficult as a dataset grows in size:
- The heap footprint of the dataset grows
- Retrieving the dataset requires downloading more bits
- Updating the dataset may require significant CPU resources or impact GC behavior
Engineers often select a hybrid approach — cache the frequently accessed data locally and go remote for the “long-tail” data. This approach has its own challenges:
- Bookkeeping data structures can consume a significant amount of the cache heap footprint
- Objects are often kept around just long enough for them to be promoted and negatively impact GC behavior
At Netflix we’ve realized that this hybrid approach often represents a false savings. Sizing a local cache is often a careful balance between the latency of going remote for many records and the heap requirement of keeping more data local. However, if you can cache everything in a very efficient way, you can often change the game — and get your entire dataset in memory using less heap and CPU than you would otherwise require to keep just a fraction of it. This is where Hollow, Netflix’s latest OSS project comes in.

Hollow is a java library and comprehensive toolset for harnessing small to moderately sized in-memory datasets which are disseminated from a single producer to many consumers for read-only access.
“Hollow shifts the scale …
datasets for which such liberation
may never previously have been considered
can be candidates for Hollow.”
Performance
Hollow focuses narrowly on its prescribed problem set: keeping an entire, read-only dataset in-memory on consumers. It circumvents the consequences of updating and evicting data from a partial cache.
Due to its performance characteristics, Hollow shifts the scale in terms of appropriate dataset sizes for an in-memory solution. Datasets for which such liberation may never previously have been considered can be candidates for Hollow. For example, Hollow may be entirely appropriate for datasets which, if represented with json or XML, might require in excess of 100GB.
Agility
Hollow does more than simply improve performance — it also greatly enhances teams’ agility when dealing with data related tasks.
Right from the initial experience, using Hollow is easy. Hollow will automatically generate a custom API based on a specific data model, so that consumers can intuitively interact with the data, with the benefit of IDE code completion.
But the real advantages come from using Hollow on an ongoing basis. Once your data is Hollow, it has more potential. Imagine being able to quickly shunt your entire production dataset — current or from any point in the recent past — down to a local development workstation, load it, then exactly reproduce specific production scenarios.
Choosing Hollow will give you a head start on tooling; Hollow comes with a variety of ready-made utilities to provide insight into and manipulate your datasets.
Stability
How many nines of reliability are you after? Three, four, five? Nine? As a local in-memory data store, Hollow isn’t susceptible to environmental issues, including network outages, disk failures, noisy neighbors in a centralized data store, etc. If your data producer goes down or your consumer fails to connect to the data store, you may be operating with stale data — but the data is still present and your service is still up.
Hollow has been battle-hardened over more than two years of continuous use at Netflix. We use it to represent crucial datasets, essential to the fulfillment of the Netflix experience, on servers busily serving live customer requests at or near maximum capacity. Although Hollow goes to extraordinary lengths to squeeze every last bit of performance out of servers’ hardware, enormous attention to detail has gone into solidifying this critical piece of our infrastructure.
Origin
Three years ago we announced Zeno, our then-current solution in this space. Hollow replaces Zeno but is in many ways its spiritual successor.
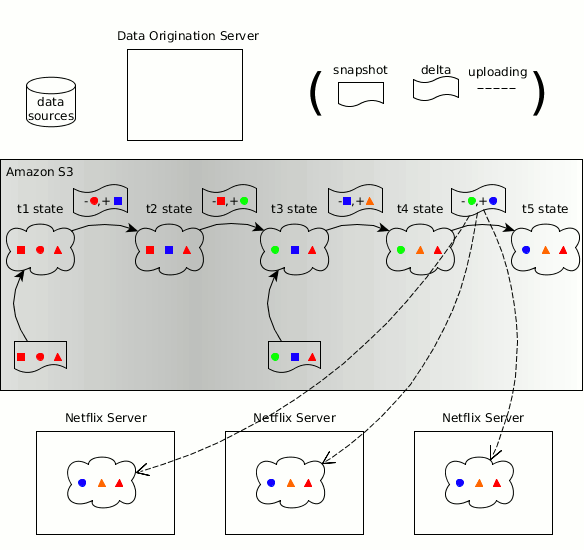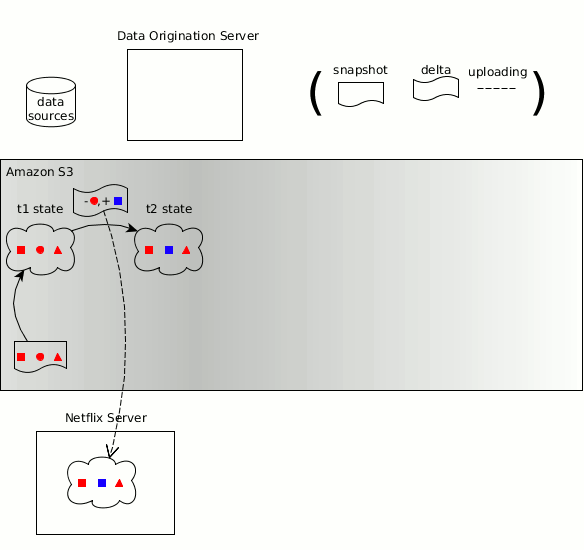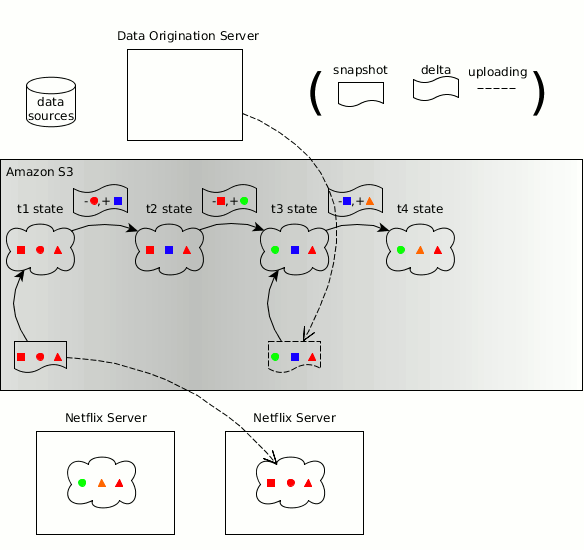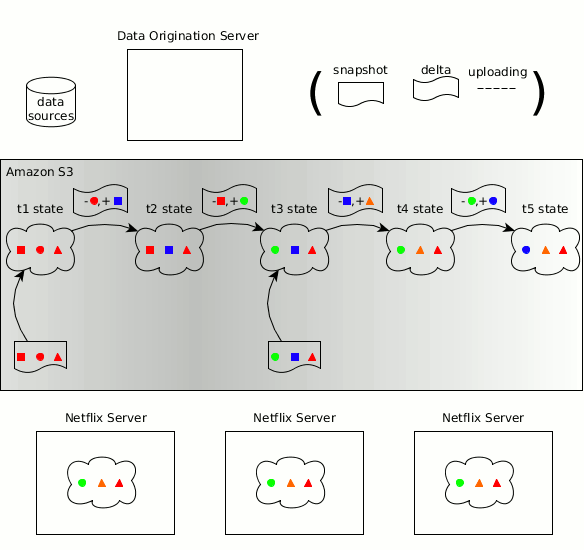
Zeno’s concepts of producer, consumers, data states, snapshots and deltas are carried forward into Hollow
As before, the timeline for a changing dataset can be broken down into discrete data states, each of which is a complete snapshot of the data at a particular point in time. Hollow automatically produces deltas between states; the effort required on the part of consumers to stay updated is minimized. Hollow deduplicates data automatically to minimize the heap footprint of our datasets on consumers.
Evolution
Hollow takes these concepts and evolves them, improving on nearly every aspect of the solution.
Hollow eschews POJOs as an in-memory representation — instead replacing them with a compact, fixed-length, strongly typed encoding of the data. This encoding is designed to both minimize a dataset’s heap footprint and to minimize the CPU cost of accessing data on the fly. All encoded records are packed into reusable slabs of memory which are pooled on the JVM heap to avoid impacting GC behavior on busy servers.

An example of how OBJECT type records are laid out in memory
Hollow datasets are self-contained — no use-case specific code needs to accompany a serialized blob in order for it to be usable by the framework. Additionally, Hollow is designed with backwards compatibility in mind so deployments can happen less frequently.
“Allowing for the construction of
powerful access patterns, whether
or not they were originally anticipated
while designing the data model.”
Because Hollow is all in-memory, tooling can be implemented with the assumption that random access over the entire breadth of the dataset can be accomplished without ever leaving the JVM heap. A multitude of prefabricated tools ship with Hollow, and creation of your own tools using the basic building blocks provided by the library is straightforward.
Core to Hollow’s usage is the concept of indexing the data in various ways. This enables O(1) access to relevant records in the data, allowing for the construction of powerful access patterns, whether or not they were originally anticipated while designing the data model.
Benefits
Tooling for Hollow is easy to set up and intuitive to understand. You’ll be able to gain insights into your data about things you didn’t know you were unaware of.
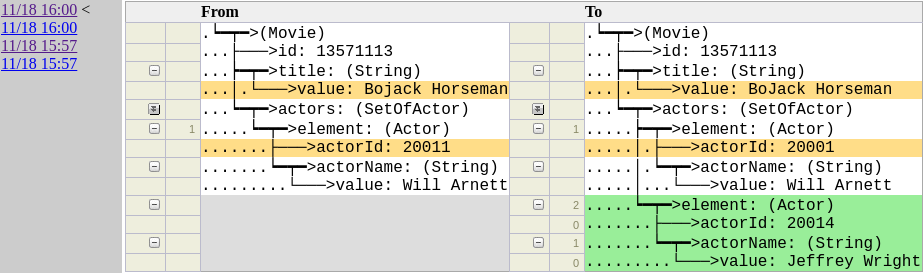
The history tool allows for inspecting the changes in specific records over time
Hollow can make you operationally powerful. If something looks wrong about a specific record, you can pinpoint exactly what changed and when it happened with a simple query into the history tool. If disaster strikes and you accidentally publish a bad dataset, you can roll back your dataset to just before the error occurred, stopping production issues in their tracks. Because transitioning between states is fast, this action can take effect across your entire fleet within seconds.
“Once your data is Hollow, it has more potential.”
Hollow has been enormously beneficial at Netflix — we've seen server startup times and heap footprints decrease across the board in the face of ever-increasing metadata needs. Due to targeted data modeling efforts identified through detailed heap footprint analysis made possible by Hollow, we will be able to continue these performance improvements.
In addition to performance wins, we've seen huge productivity gains related to the dissemination of our catalog data. This is due in part to the tooling that Hollow provides, and in part due to architectural choices which would not have been possible without it.
Conclusion
Everywhere we look, we see a problem that can be solved with Hollow. Today, Hollow is available for the whole world to take advantage of.
Hollow isn’t appropriate for datasets of all sizes. If the data is large enough, keeping the entire dataset in memory isn’t feasible. However, with the right framework, and a little bit of data modeling, that threshold is likely much higher than you think.
Documentation is available at http://hollow.how, and the code is available on GitHub. We recommend diving into the quick start guide — you’ll have a demo up and running in minutes, and a fully production-scalable implementation of Hollow at your fingertips in about an hour. From there, you can plug in your data model and it’s off to the races.
Once you get started, you can get help from us directly or from other users via Gitter, or by posting to Stack Overflow with the tag “hollow”.

