

By: Apurva Kansara
Here, I will describe our approach to extract contextual metadata from video assets to enable an improved Netflix user experience across the large catalog we serve.
Part 1: Detecting End-Sequences
When you finish watching a movie, we are able to provide a unique post-play experience as illustrated below in two examples. The user is presented with the next in a series of, or content similar to, the most recently seen video. Yet, the primary issue similarly remains isolating the salient parts of series and movies without the mind-boggling challenge of manually tagging the large and ever-changing catalog for the end points. In other words, we must devise a strategy for detecting when a video ends and the end-sequence begins. Interestingly, the end-sequence is unique in a few striking ways. First, that it appears at the end of the movie. Second, it almost always is comprised of text. Finally, there is very little variation between contiguous frames. Using all three of these conditions, we created an algorithm that successfully extracts the beginning of the end-sequence.
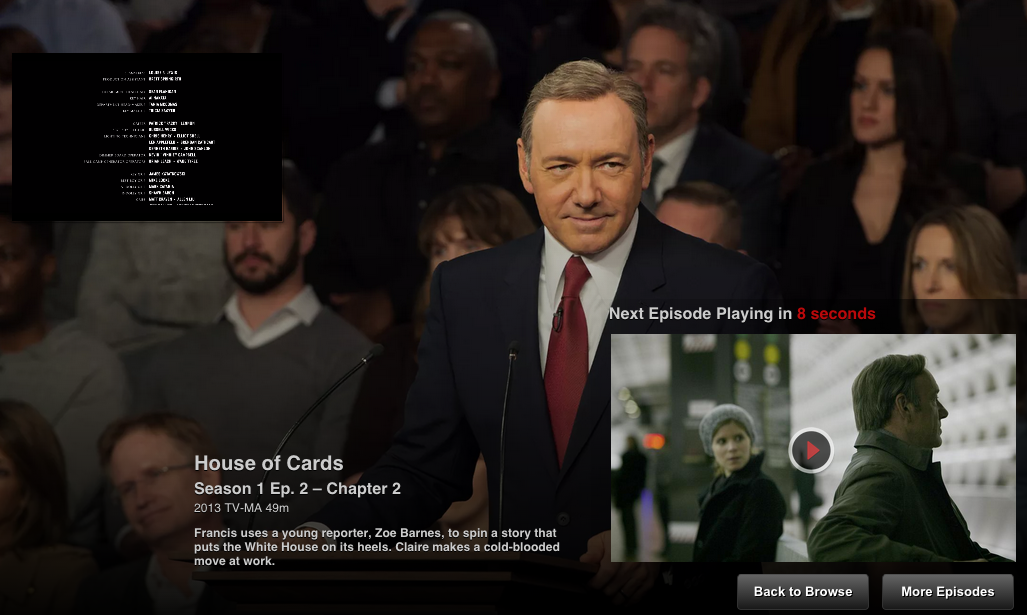

Two examples of Netflix post-play experiences
Below you'll find an example of text-detected regions (highlighted with yellow rectangles) on the end-sequence of Orange is the New Black:

Automated text detection of end sequence
Part 2: Detecting Similar Frames Across Multiple Video Assets
At Netflix, for a given video, we have several assets encoded for different countries and locales. There are many applications to detect similar frames across multiple video assets.
We extract visual fingerprints of a collection of certain frames. We can then use these fingerprints as comparative models- if similar frames appear in the rest of the videos, we can mark them as the ending of the start-sequence.
Let’s take an example: Let’s say Fig. 1A is the last frame of the title sequence of our favorite TV series. We'll call it our "Reference Frame," which we'll want to match with the rest of the episodes. In this case, we extracted an image histogram, to become our reference frame, as a marker of the fingerprint. Now, we will compare this fingerprint with another episode (Fig. 1B) of the same series. Given that both fingerprints are similar, we can walk through the rest of the episodes to mark them as identical/similar frames. Besides detecting the start sequence, this approach can be used to other interesting points within video.
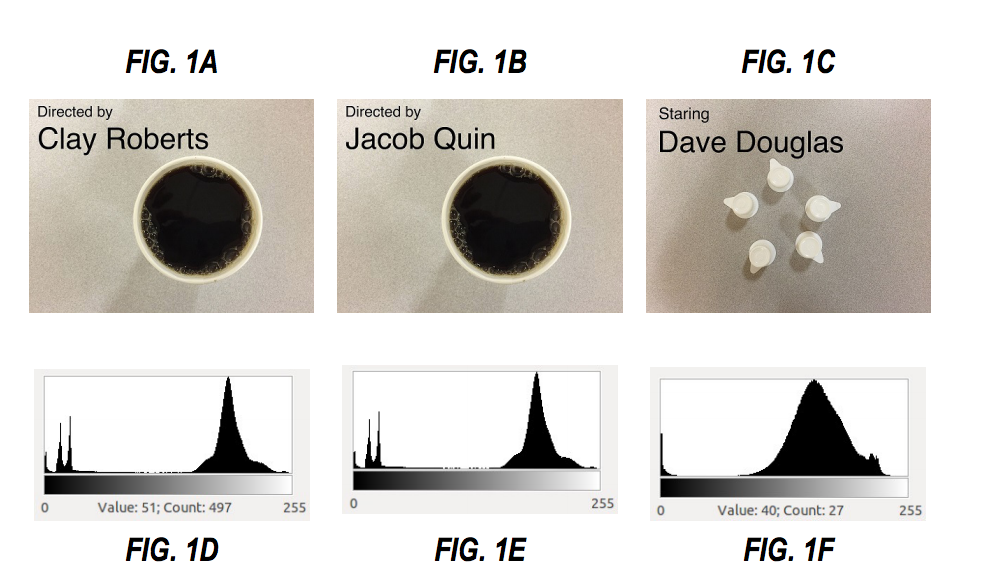
Histogram based fingerprints of video frames
Summary
Here, we have outlined two classes of algorithms that allow us to efficiently extract metadata of video assets allowing us to create a unique, uninterrupted viewing experience at Netflix.
التصنيف:
content platform engineering

